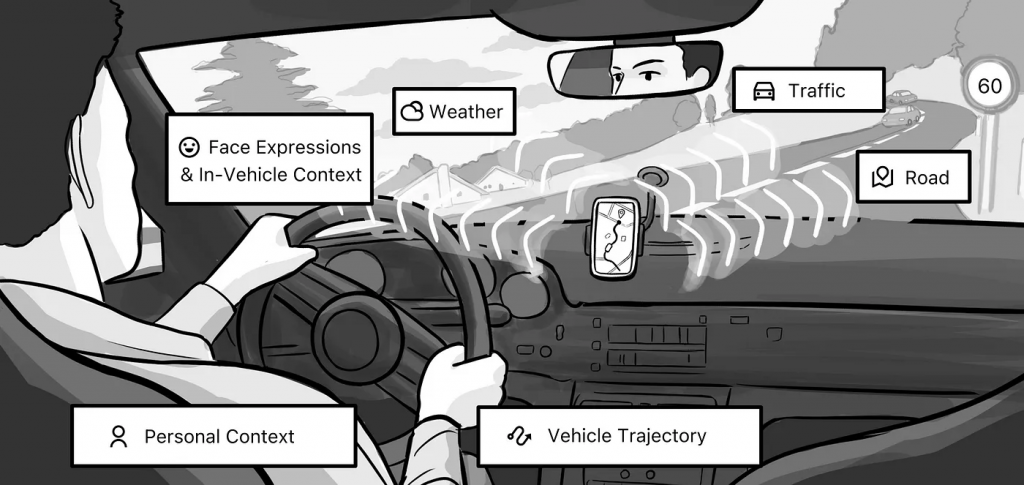
Imagine it’s a rainy morning, and you are spending your time in a traffic jam on Autobahn 8 near Stuttgart. The whole working week is only about to start, with many appointments scheduled back-to-back. You’re already late for your first appointment with your manager’s manager. How do you think this situation would make you feel? Most likely not happy and quite stressed. From reading this anecdote, how do you come to this conclusion? It’s all about the context — the information that describes the situation you are currently experiencing.
This example made us curious: Why do so many companies and individuals try to infer emotions from observing the driver with cameras or microphones? Our studies found that most people look neutral and drive without emotional expressiveness. Car manufacturers use in-car microphones and computer vision to detect emotions by analyzing the driver’s voice and facial expressions. However, most people only talk while driving, especially when driving alone. Filming the driver and the car interiors poses privacy threats and provide little utility for emotion detection. Hence, we asked ourselves how to exploit driver context for emotion recognition.
We proposed a novel approach to detect emotions in the wild. We use a smartphone, which is a device that almost everyone has access to sensors such as GPS, camera, and microphone to derive contextual features. The context can give insights into a person’s emotional state. The following section will present the various context streams available for emotion prediction.
GPS: We use a smartphone’s GPS sensor to determine travel speed and acceleration. This information helps to determine if and how the user is driving, walking, or using public transport. Furthermore, via reverse-geocoding, the weather (degree of sunlight, raininess, temperature outside) and traffic flow (onset of traffic jam, reduced speed on road segment vs. average speed) of the location via Google or Microsoft APIs give an environmental (driving) context. OpenStreetMaps also allows for a better understanding of the static road context, such as road type, speed limits, traffic signs, and the number of available lanes. At last, the GPS location can be used to get a satellite image of the surroundings and deduct the average greenness. In total, a GPS position enables to proxy of the person’s activity, current weather conditions, surrounding traffic flow, road types, and greenness.
Camera: Usually, the camera assesses the driver’s facial expressions and derives its emotion. As the driver mostly looks unexpressed, facial expressions mostly return neutral emotional states, although other emotions may be present. Yet, we can access the backward-camera frames and analyze the visual driving scene: the number of cars, trucks, and bicycles are extracted via computer vision approaches (e.g., VGG-16 trained on ImageNet). This visual scene analysis provides a more direct signal of how complex the scene in the wild for the person is, which directly relates to emotional feelings. A smartphone’s camera can also determine the weather conditions outside. For instance, the driver might feel sad if it’s raining, but if the sun is shining, they might feel happy.
Voice: A smartphone’s microphone can capture the driver’s voice and detect changes in tone or pitch. Mostly, people do not speak while driving, limiting the performance of dynamic analysis of the signals. This information could be used to determine if the driver feels happy, sad, angry, or any other emotion. In our case, we use the microphone only for getting ground-truth labels.
Static Smartphone: We are capturing the daytime using the smartphone timestamps, providing the system information whether it is early in the morning (and people are potentially moodier).
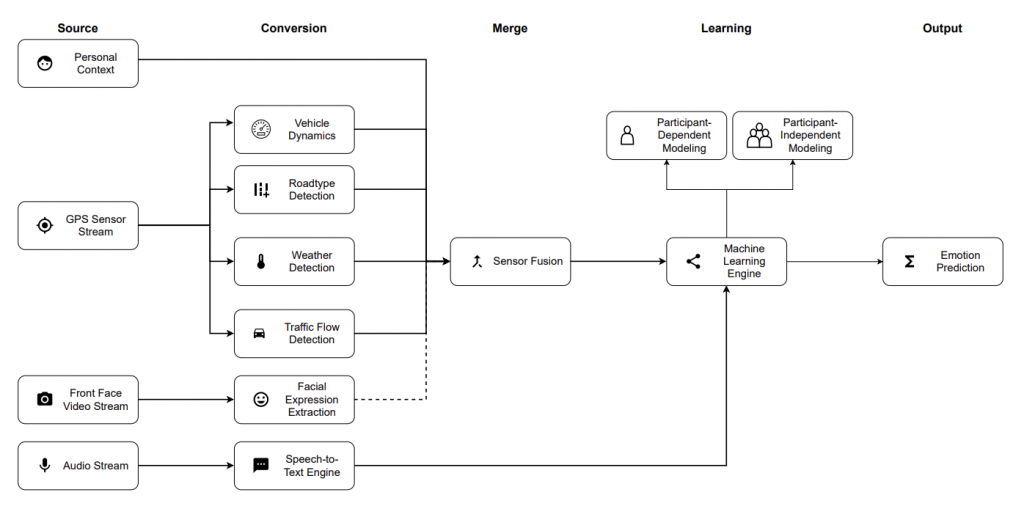
In a user study, we validated whether contextual signals can predict emotions in the wild. We provided 27 participants with our smartphone app gathering real-time contextual signals and asked them to provide their current emotional state every 60s verbally. The verbally provided emotion represents the ground-truth label of emotions in the wild.
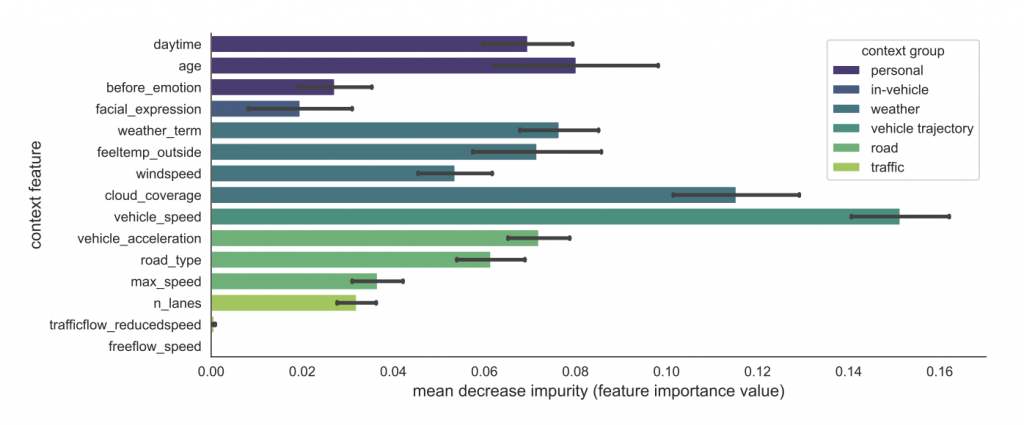
We train a random forest classification model to predict emotions for all participants. We investigate how powerful each feature was for creating a classification model. Overall, we detect the highest feature importance of vehicle trajectory variables (e.g., vehicle speed). This might be because ‘happy’ emotions are often reported in unhindered speed scenarios. Similarly, higher negative emotions (i.e., ‘anger’ and ‘fear’) are frequently observed during unforeseen traffic incidents (e.g., increased traffic densities or red light series) that require high cognitive demands of the driver.
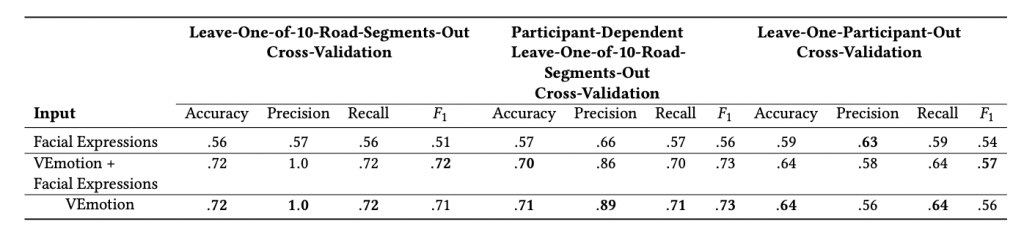
Our analysis shows that contextual emotion recognition is significantly more robust than facial recognition, leading to an overall improvement of 7% using a leave-one-participant-out cross-validation. Overall, our contextual features make it possible to predict emotions in real time for unseen roads and drivers. The overall accuracy of emotions is 71.70%. In other words, it is 29% better than relying on the ‘facial expression’ engine alone. We validated the facial expression engine using other common facial expression classifier systems (AWS, EmoPy), but the results remained the same.
Empathic interface designers can tailor the driver experience by changing the music playing or showing more relevant advertisements. In conclusion, using smartphones to sense human emotions is a relatively new but promising field. With advancements in machine learning and artificial intelligence, this technology will likely become more accurate and widely used. Whether it’s to improve the driver experience or to understand human behavior better, using smartphones to sense human emotions will significantly impact the future.
Authors: David Bethge (LMU Munich), Thomas Kosch (HU Berlin), Tobias Grosse-Puppendahl (Dr. Ing. h. c. F. Porsche AG). This post is based on a joint post from Medium.
References:
[1] David Bethge, Thomas Kosch, Tobias Grosse-Puppendahl, Lewis L. Chuang, Mohamed Kari, Alexander Jagaciak, and Albrecht Schmidt. 2021. VEmotion: Using Driving Context for Indirect Emotion Prediction in Real-Time. In The 34th Annual ACM Symposium on User Interface Software and Technology (UIST ‘21). Association for Computing Machinery, New York, NY, USA, 638–651. https://doi.org/10.1145/3472749.3474775
[2] David Bethge, Luis Falconeri Coelho, Thomas Kosch, Satiyabooshan Murugaboopathy, Ulrich von Zadow, Albrecht Schmidt, and Tobias Grosse-Puppendahl. 2023. Technical Design Space Analysis for Unobtrusive Driver Emotion Assessment Using Multi-Domain Context. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 6, 4, Article 159 (December 2022), 30 pages. https://doi.org/10.1145/3569466
[3] Bethge, D., Patsch, C., Hallgarten, P., & Kosch, T. (2023, April). Interpretable Time-Dependent Convolutional Emotion Recognition with Contextual Data Streams. In Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems. https://doi.org/10.1145/3544549.3585672



{kind=link}